
Intelligence Artificelle
23 DEC 2025
Le premier dataset open source de traduction français ↔ dioula
La publication de hf_fr_dioula_full marque une étape importante : pour la première fois, un dataset de traduction français ↔ dioula est disponible en open source, prêt pour l’entraînement de modèles d’IA.
Introduction — Une première nécessaire
L’intelligence artificielle progresse vite, mais elle progresse de manière inégale.
Derrière les démonstrations spectaculaires et les modèles toujours plus puissants se cache une réalité plus simple : sans données, il n’y a pas d’IA utile.
Derrière les démonstrations spectaculaires et les modèles toujours plus puissants se cache une réalité plus simple : sans données, il n’y a pas d’IA utile.
Pendant longtemps, les langues africaines sont restées en marge de cet écosystème. Non pas parce qu’elles manquent de locuteurs ou d’usage réel, mais parce qu’elles manquent de datasets accessibles, structurés et exploitables.
La publication de hf_fr_dioula_full s’inscrit dans cette logique.
Il ne s’agit pas d’un modèle, ni d’un produit fini, mais d’une brique fondamentale : un dataset de traduction français ↔ dioula, open source, prêt à être utilisé pour l’entraînement et le fine-tuning de modèles.
Pour la première fois, une base de données de cette ampleur est mise à disposition publiquement pour cette paire de langues.
La publication de hf_fr_dioula_full s’inscrit dans cette logique.
Il ne s’agit pas d’un modèle, ni d’un produit fini, mais d’une brique fondamentale : un dataset de traduction français ↔ dioula, open source, prêt à être utilisé pour l’entraînement et le fine-tuning de modèles.
Pour la première fois, une base de données de cette ampleur est mise à disposition publiquement pour cette paire de langues.
L’invisibilité des langues africaines dans l’IA
L’écosystème des données en intelligence artificielle est profondément déséquilibré.La majorité des datasets publics et des benchmarks se concentrent sur quelques langues dominantes : l’anglais, le français, le chinois, parfois l’espagnol ou l’allemand. Ce déséquilibre a une conséquence directe :
les modèles sont performants là où les données sont abondantes, et approximatifs — voire inutilisables — ailleurs.
Les langues africaines, et le dioula en particulier, sont rarement présentes dans les grands corpus publics. Lorsqu’elles le sont, c’est souvent de manière fragmentaire, non standardisée ou difficilement exploitable à l’échelle industrielle.
Publier un dataset, dans ce contexte, n’est pas un détail technique. C’est un acte structurant : rendre la langue visible, mesurable et exploitable par les systèmes d’IA.
les modèles sont performants là où les données sont abondantes, et approximatifs — voire inutilisables — ailleurs.
Les langues africaines, et le dioula en particulier, sont rarement présentes dans les grands corpus publics. Lorsqu’elles le sont, c’est souvent de manière fragmentaire, non standardisée ou difficilement exploitable à l’échelle industrielle.
Publier un dataset, dans ce contexte, n’est pas un détail technique. C’est un acte structurant : rendre la langue visible, mesurable et exploitable par les systèmes d’IA.
Pourquoi le dioula
Le dioula n’a pas été choisi au hasard. C’est l’une des langues les plus parlées en Afrique de l’Ouest et une langue de communication quotidienne : commerce, transport, échanges sociaux, administration informelle. C’est une langue vivante et fonctionnelle, utilisée pour résoudre des problèmes concrets, bien au-delà des cadres institutionnels. Malgré cela, le dioula reste très peu représenté dans les ressources numériques et les datasets publics. Les outils de traduction et les systèmes d’IA le prennent rarement en charge de manière fiable, faute de données structurées. Travailler sur le dioula, c’est donc répondre à un besoin réel : rendre l’IA plus accessible, plus locale et plus utile.
Dans ce contexte, hf_fr_dioula_full constitue une première brique pour construire des systèmes de traduction et des applications adaptées aux usages du terrain.
Dans ce contexte, hf_fr_dioula_full constitue une première brique pour construire des systèmes de traduction et des applications adaptées aux usages du terrain.
Présentation du dataset hf_fr_dioula_full
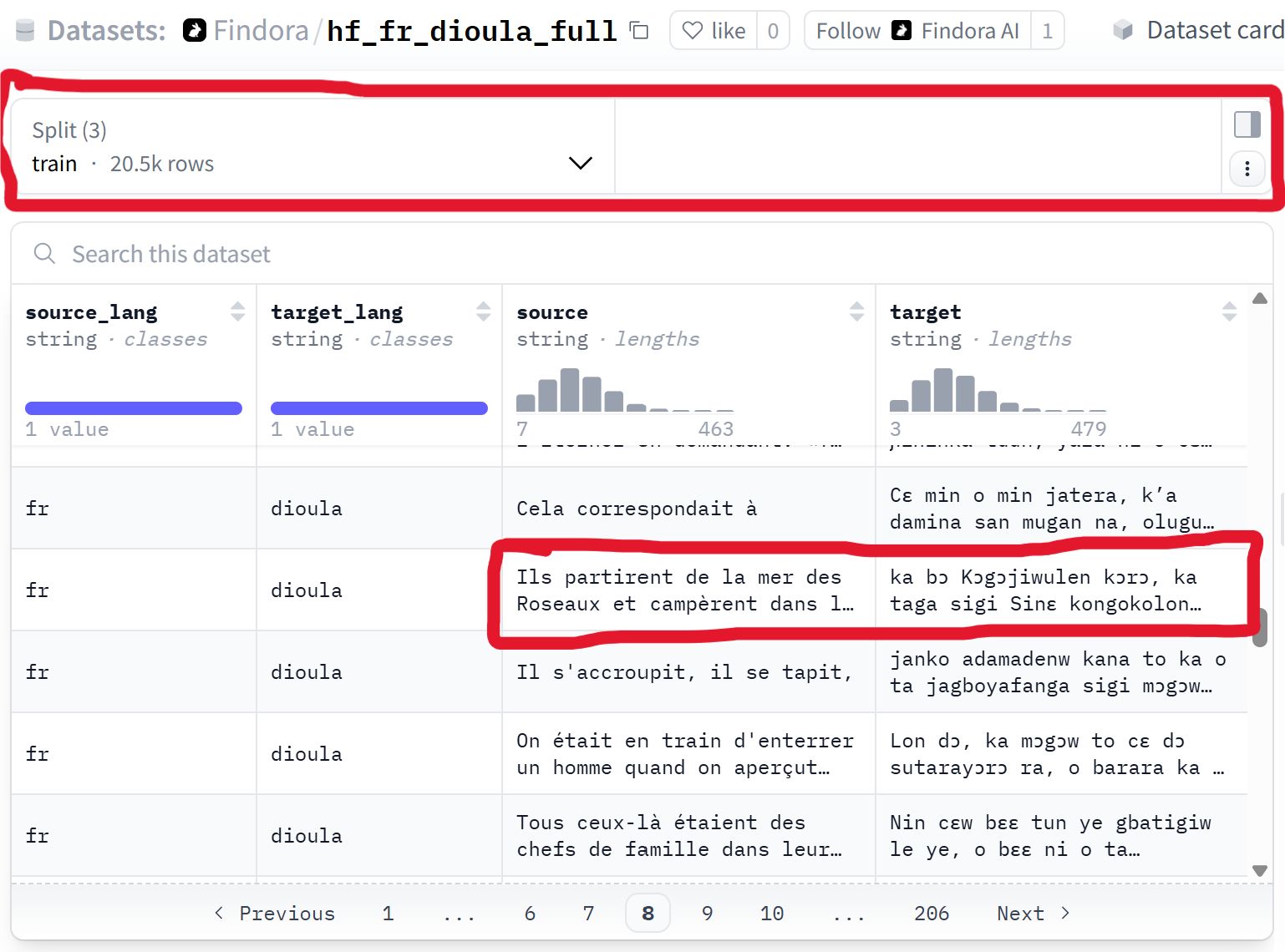
hf_fr_dioula_full est un dataset de traduction français ↔ dioula publié en open source sur Hugging Face. Il contient plus de 25 000 paires de traduction, réparties de manière standard pour l’entraînement et l’évaluation de modèles :
+25 000 paires pour l’entraînement
2 560 paires pour la validation
2 570 paires pour les tests
Le dataset est structuré pour être directement exploitable dans des pipelines de machine learning et de NLP. Il peut être utilisé pour entraîner ou affiner des modèles de traduction, des modèles multilingues ou des systèmes conversationnels.
L’ensemble est publié sous licence Apache 2.0, ce qui autorise un usage académique et commercial, sans restriction.
+25 000 paires pour l’entraînement
2 560 paires pour la validation
2 570 paires pour les tests
Le dataset est structuré pour être directement exploitable dans des pipelines de machine learning et de NLP. Il peut être utilisé pour entraîner ou affiner des modèles de traduction, des modèles multilingues ou des systèmes conversationnels.
L’ensemble est publié sous licence Apache 2.0, ce qui autorise un usage académique et commercial, sans restriction.
À quoi sert concrètement ce dataset
Le dataset hf_fr_dioula_full peut être utilisé comme base pour plusieurs cas d’usage concrets :
Entraîner des modèles de traduction français ↔ dioula
Affiner des modèles multilingues existants
Construire des assistants conversationnels locaux
Intégrer le dioula dans des systèmes de recherche ou de RAG
Préparer des applications vocales à terme (speech-to-text / text-to-speech)
En fournissant des données structurées et exploitables, ce dataset permet de passer de l’expérimentation à des usages réels, adaptés au terrain.
Entraîner des modèles de traduction français ↔ dioula
Affiner des modèles multilingues existants
Construire des assistants conversationnels locaux
Intégrer le dioula dans des systèmes de recherche ou de RAG
Préparer des applications vocales à terme (speech-to-text / text-to-speech)
En fournissant des données structurées et exploitables, ce dataset permet de passer de l’expérimentation à des usages réels, adaptés au terrain.
Conclusion
Avec hf_fr_dioula_full, l’enjeu n’est pas de proposer une solution clé en main, mais de poser une base. Sans données, il n’y a pas de modèles fiables, et sans modèles, pas d’usages locaux pertinents.
Ce dataset marque une première étape vers une intelligence artificielle plus inclusive, plus ancrée dans les réalités linguistiques africaines.
Ce dataset marque une première étape vers une intelligence artificielle plus inclusive, plus ancrée dans les réalités linguistiques africaines.

